« September 2009 | Main | July 2009 »
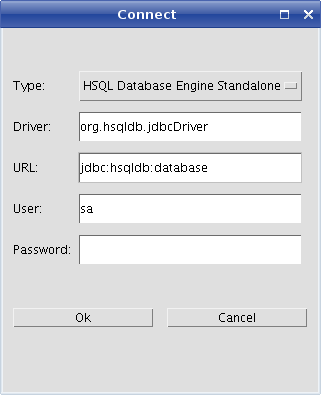
Tuesday, August 18, 2009I Did It AgainI did it again. I left off the front of the URL for the images on the entry for Hacking the Database and the archives and entry pages couldn't find the images. I fixed it. Monday, August 17, 2009Be Careful of Links to FilesI had an interesting problem with the blog. In an entry concerning my new search program I put a link to the file tamb_search.html which was imported into the blog root directory. The link worked fine on the main page, but on the archive page and the entry page it failed fo find the file because it was looking for it in those local directories. When linking to a file at the top in a blog entry, it is necessary to link to the full URL path to avoid the problem. Friday, August 14, 2009Hacking Thingamablog's DatabaseI have hacked into the database used by Thingamablog. The blog entries are stored in a database so that the software can extract the entries into the various pages, such as the main page, the archive page, the entry pages, etc. The database used by Thingamablog is the HSQLDB. It is a 100% java, embedded database. It interprets normal SQL commands. The database engine is contained in the jar file, hsqldb.jar, in the lib directory where you installed the Thingamablog program. It turns out that there is a database manager program embedded in the same jar file, and you can use it to look in the database. You just need to run the database manager and connect it to your database and you are in. On my system, the Thingamablog program is installed here: /home/brian/apps/thingamablog/thingamablog-1.1b6/ My database, the thing that actually contains the entries for my blogs is here: /home/brian/blogsdatabase/database So to run the program and connect to my database, first I open a command line terminal and cd to my database directory: cd /home/brian/blogsdatabase/database You must be in the directory that contains the database files:
to make this work, not in the directory above it. Then run the database manager program directly from the hsqldb jar file: java -cp /home/brian/apps/thingamablog/thingamablog-1.1b6/lib/hsqldb.jar org.hsqldb.util.DatabaseManager& The program is written in Java, so we run it with the java runtime. Since my blog is on a Linux computer, the & at the end of the command runs the program in the background and gives back the command line prompt in the terminal emulator. It isn't necessary to run the program. If you are on a Windows system, you can run the program the same way using a DOS command window with a command like: java -cp C:\Apps\Thingamablog\src\thingamablog-1.1b6\lib\hsqldb.jar org.hsqldb.util.DatabaseManager or something similar, depending on where you installed Thingamablog. Once you run the database manager, it will post a connection dialog. Using the selector box at the top select "standalone" mode, and in the URL field enter the name "database", which is the name Thingamoblog uses for its database. Here is the dialog:
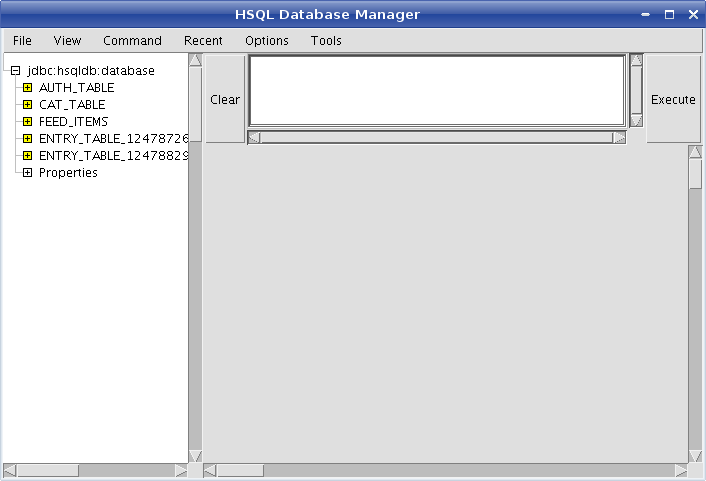
Once you have the connection set up, click on OK and you should see the database manager dialog showing the tables in the database:
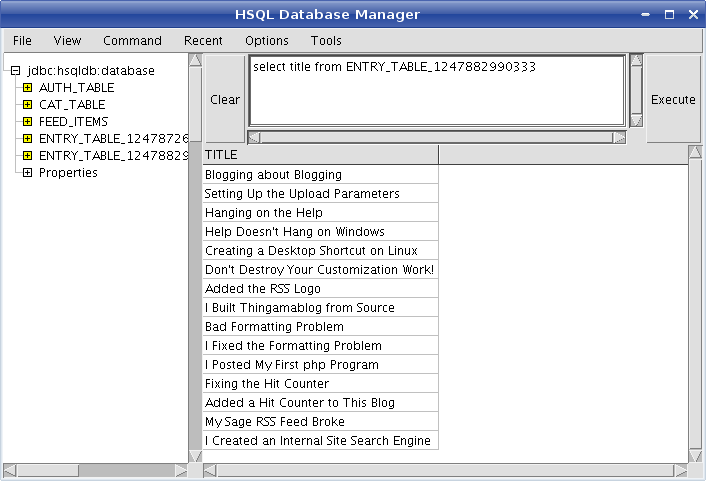
At this point, you can enter some SQL commands to poke around and see what the contents of the database are, like this:
That is all there is to it. Oh, yes, and if you are not very familiar with SQL, you might not want to fool around too much. If you change anything in the database, you could blow out your entire blog. Be careful! Don't change the contents of the database! You have been warned! Don't come crying to me if you lose everything. You might want to do a complete backup of your blog before you try this. Sunday, August 09, 2009I Created an Internal Site Search EngineI have written a search engine to search just this blog for text strings. Previously I had posted a site search which used Google, but that searches my entire domain name, thekimerers.com. What I wanted was a search engine that will search only this blog. Besides, it took a month for the Google bots to find this blog so it's search engine was useless during that time. So I wrote my own. Since I changed my web page type from .html to .php I can now write programs in php to do whatever I want. And that is what I did. I wrote a program to search this site and called it "tamb_search.php". Click here to view the program. The program is invoked from a form on the main page. I posted it to the main page by adding a new custom tag called "PhpSearch". The text in that tag is the following:
<div class="sidetitle">Internal Site Search</div> <div class="side"> <center> <table border="3" align="center" CELLPADDING="10"> <tr><td align="center"> <form action="tamb_search.php" method="post"> <input type="text" name="pattern" /><br><br> <input type="submit" value="Search Thingamablog Blog"/> </form> </tr></td> </table> </center> </div> When you enter a search value and click on the button, it takes you to a new page with the search results and another form to do another search. The form on the page tamb_search.php is self-referential, meaning that it posts to itself, so you can keep searching from the same page as many times as you like. Monday, August 03, 2009My Sage RSS Feed BrokeWhen I switched over from .html files to .php files my Sage RSS feed broke. What happened was that clicking on the feed name showed me an old page with links to the old .html files, which no longer existed. After a few sessions with Thingamablog and FileZilla I convinced myself that that the rss.xml file was updating properly when I published. I set Thingamablog to publish the full entries in the rss.xml file and uploaded the whole blog. After publishing the blog and then downloading rss.xml it was clear that the file had been properly updated. When I went back to my RSS Sage feed, I got the same old page. Stale info and stale pointers. And no obvious way to remove the cached file. I tried refreshing the page, but Sage was showing a local file with the information in it, and nothing changed. I finally fixed it by going out to the blog page and clicking directly on the "Syndicate this site" link to the rss.xml. Firefox showed me the same old stale file. But this time when I hit the refresh button, the file was updated. Then, when I went back to my Sage RSS reader, it had the new information. Very strange. Sunday, August 02, 2009Added a Hit Counter to This BlogI added a hit counter to this blog. First I changed all of the file extensions in the blog from ".html" to ".php". Then I imported a file called "simplehitcounter.php" into the "web" folder. The file contains the php code that I posted yesterday. Then I created a new custom tag "HitCounter" with the following contents, and included it in the main page template just above the <$Copyright$> tag. Edit: I should have mentioned that the Copyright tag is also one of my custom tags. It goes at the bottom of the "contents" ID and before the "links" ID in the template. Here are the contents of the new HitCounter custom tag:
<div align="center">
<p>
<b>
We have had the pleasure of hosting
<?php
include ("simplehitcounter.php");
?>
guests since this site was created on July 17, 2009.
</b>
</p>
</div>
Saturday, August 01, 2009Fixing the Hit CounterI added some code to the hit counter that I posted in my previous entry. In this case, I really did write the code that I added. The new code checks the IP address of the computer accessing the site, and if it is the same IP as last time, the hit counter is not incremented. So now it is not possible to just sit on the site and bump up the counter. The code stores the IP in a file called "visitor.txt" and checks it at the next visit to see if it is the same computer. I have seen php hit counters that keep all of the IP's in a file and never bumps the counter if that IP ever goes to the site ever again, but that is not what I wanted to do. So I wrote my own. I guess I am now a php programmer. This has been an exercise in learning php coding so that I can write other functions for this blog such as a search function (Google has not found me yet, so it isn't doing it for me). Here is the code for the hit counter. Go ahead and use it if you want to.
<?php
$file = 'counter.txt';
$visitor_file = 'visitor.txt';
// Create the counter file if not there
if(!file_exists($file))
{
$handle = fopen($file, 'w');
fwrite($handle, 0);
fclose($handle);
}
// Create the visitor file if not there
if(!file_exists($visitor_file))
{
$vhandle = fopen($visitor_file, 'w');
fwrite($vhandle, 0);
fclose($vhandle);
}
// Get the previous visitor from the file
$last_visitor = file_get_contents($visitor_file);
// Get the current visitor from the server
$current_visitor = $_SERVER["REMOTE_ADDR"];
// Update the counter only if the two are different
if(!($last_visitor == $current_visitor))
{
$count = file_get_contents($file);
// Trim the newline if one is there. A newline
// messes up the arithmetic operation on the string
$count = trim($count);
$count++;
// Update the counter value in the file
if(is_writable($file))
{
$handle = fopen($file, 'w+');
fwrite($handle, $count);
fclose($handle);
}
else
{
echo 'Could not increment the counter!<br />';
}
// Update the visitor file with current visitor
if(is_writable($visitor_file))
{
$vhandle = fopen($visitor_file, 'w+');
fwrite($vhandle, $current_visitor);
fclose($vhandle);
}
else
{
echo 'Could not save current visitor!<br />';
}
}
else
{
// Report what is in the count file without changing it.
$count = file_get_contents($file);
// Trim the newline if one is there. A newline
// messes up the arithmetic operation on the string
$count = trim($count);
}
echo number_format($count);
?>
This site and all of its contents are copyright Brian S. Kimerer 2009 |
|
I am a software engineer by trade. For fun I build and play banjos and paint pictures. To see some of my work, click on the link that says "My Web Site" in the Links section of this page.
Favorite Links
Archives
August 2010
July 2010 June 2010 May 2010 March 2010 January 2010 November 2009 October 2009 September 2009 August 2009 July 2009 Archive Index Google Site Search
Credits
|